Multipart uploads on Sia using Filebase and the AWS CLI


One of the most commonly used tools for transferring data to object storage services is the AWS CLI (Command Line Interface). This is a tool developed by Amazon and is largely based on the Python botocore library. The CLI features several commands that allow you to manage objects and buckets. Fortunately, it can be configured to point to any S3-compatible object storage service, including Filebase.
This tool is especially popular amongst developers and IT administrators. It is useful because it’s invoked as a command line program. This allows for it to be easily integrated with backup and other types of custom scripts. One common example would include a nightly backup script that runs via a cron job, backing up a servers hard drive to a storage bucket.
The AWS CLI is certified for use with Filebase.
To use it with Filebase, you can follow the configuration steps below. Before running through any of these steps, you will need to ensure you have the CLI properly installed. You can visit the following page for install instructions: https://aws.amazon.com/cli/
Configuration
There are three configuration values that need to be passed to the AWS CLI to use it with Filebase. They are:
- S3 API Access Key ID
- S3 API Secret Access Key
- S3 API Endpoint
The Access Key ID and Secret Access Key can be stored in a configuration file. However, the API endpoint will need to be passed in with every command. There are ways to avoid this by using 3rd party plugins, such as awscli-plugin-endpoint. We will discuss how to do this in a future blog post.
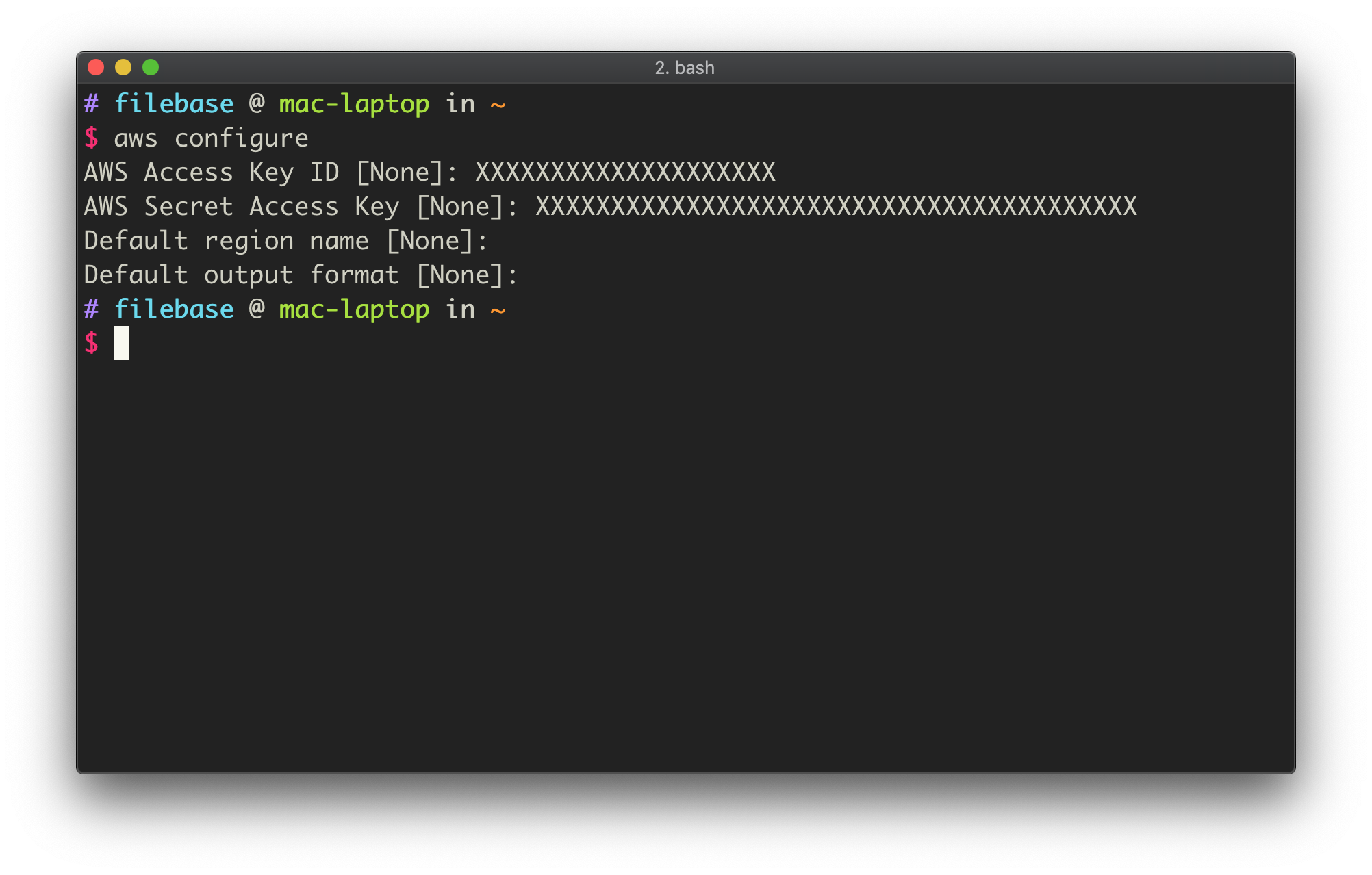
To setup our access keys, we will open a new terminal window. From there, we can run:
aws configureThis will trigger a prompt. Enter your Access Key ID and Secret Access Key. You can leave the region and output format blank by simply hitting enter.
Once the above steps are complete, we are ready to move onto interacting with the Filebase S3 API.
Create a new bucket
Let’s start out by creating a new bucket for this tutorial, named my-test-bucket. To create a new bucket, the following command should be run:
aws --endpoint https://s3.filebase.com s3 mb s3://my-test-bucket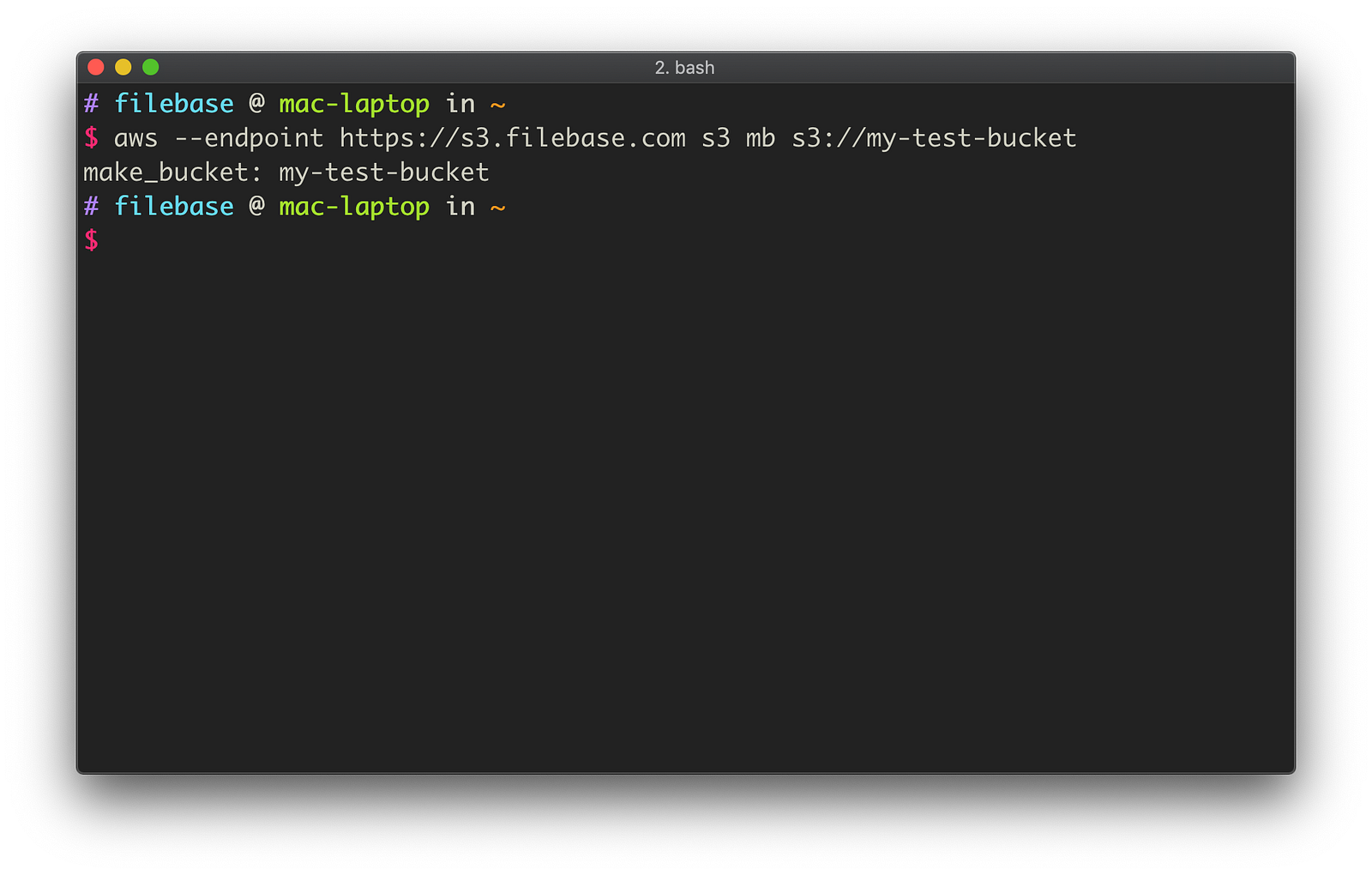
Listing Buckets
Now that we’ve created a new bucket, let’s verify it shows up under our account. The s3 ls command will list all the buckets tied to your account:
aws --endpoint https://s3.filebase.com s3 ls
Once the above command is run, we should see a list of buckets returned. This is a list of buckets that you own. As you can see below, our new bucket now appears on this list.
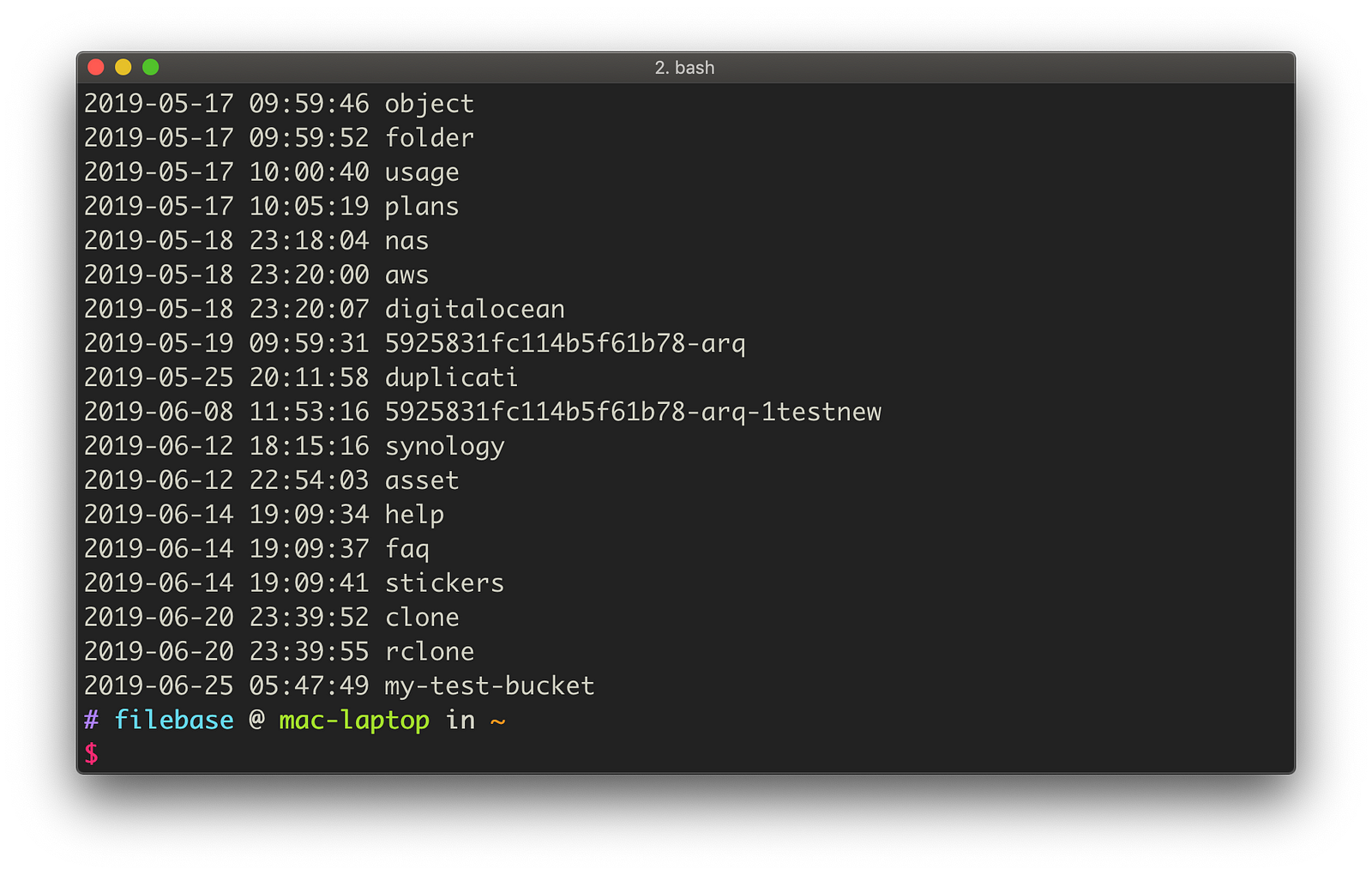
List bucket contents
Next let’s try listing the contents of our new bucket. It should be empty since it’s brand new, but let’s verify that.
To list the contents of a specific bucket, run the following:
aws --endpoint https://s3.filebase.com s3 ls s3://my-test-bucket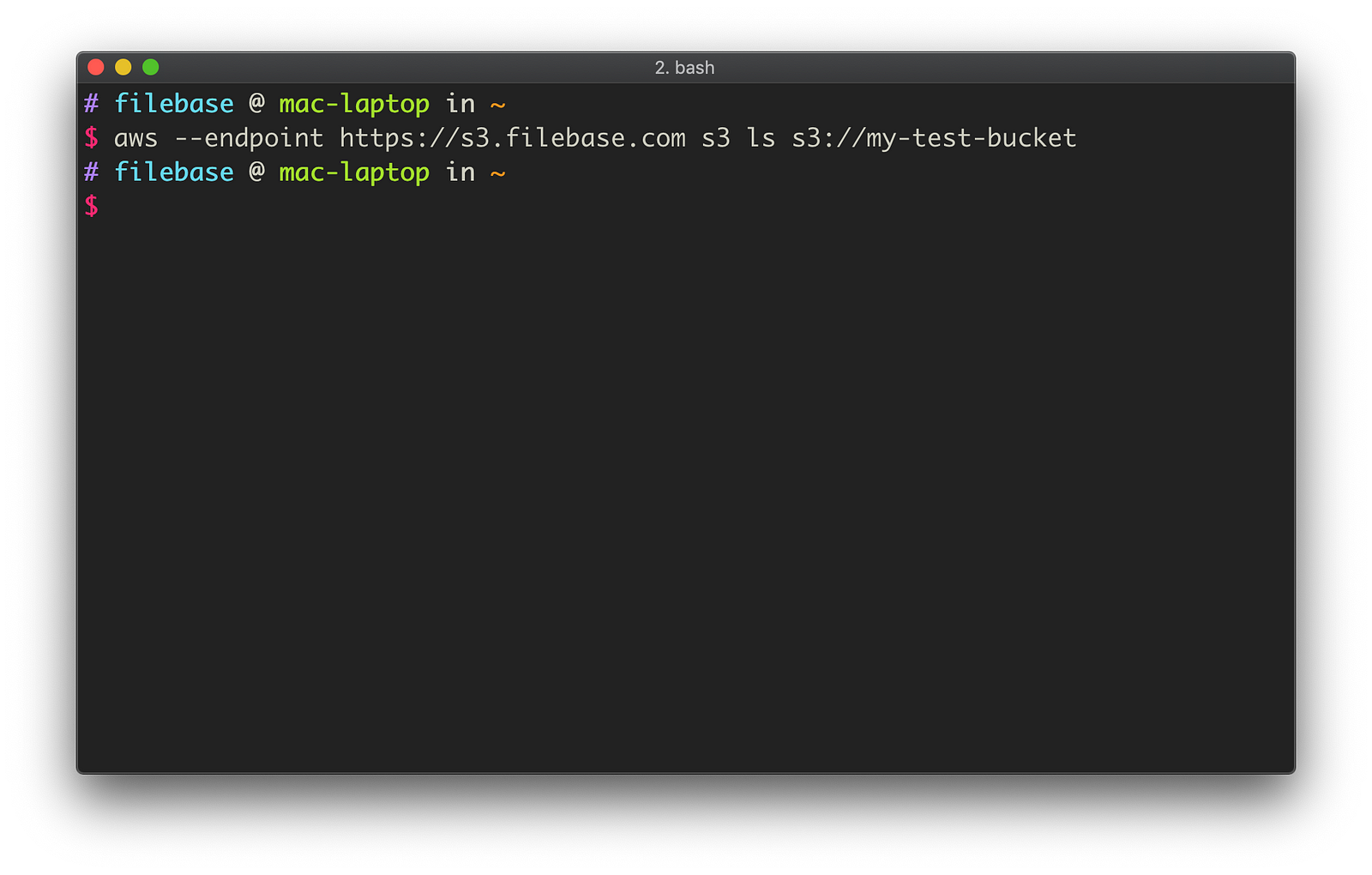
An empty response is returned, confirming that our new bucket is indeed empty.
Uploading files to a bucket
You can upload a single file or multiple files at once when using the AWS CLI. To upload multiple files at once, we can use the s3 sync command. In this example, we will upload the contents of a local folder named my-test-folder into the root of our bucket.
aws --endpoint https://s3.filebase.com s3 sync my-test-folder/ s3://my-test-bucket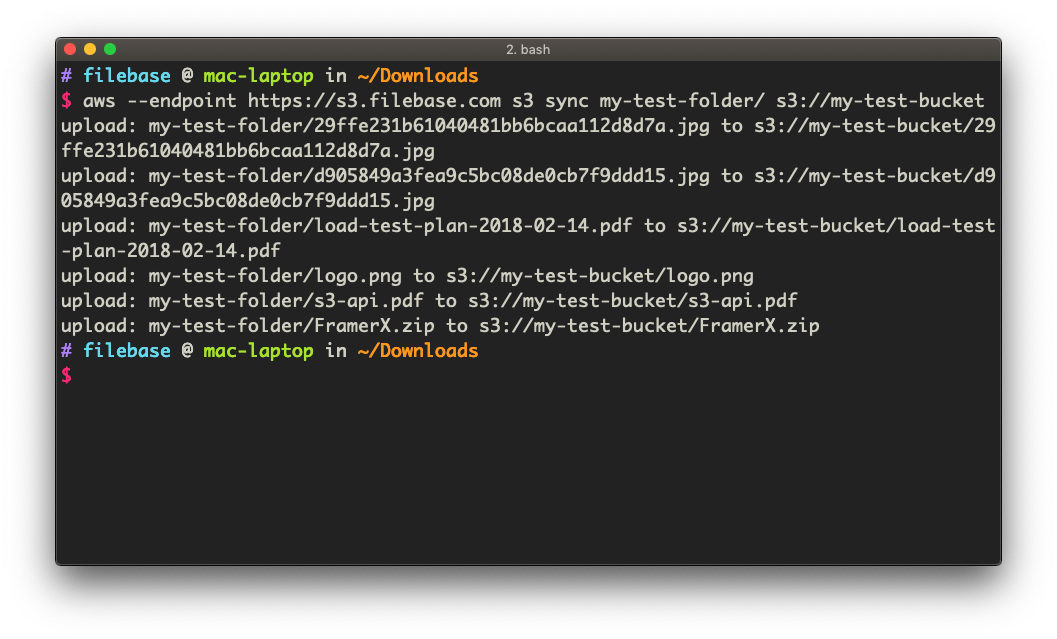
Once the upload has completed, we can list the contents of the bucket using the S3 API to confirm:
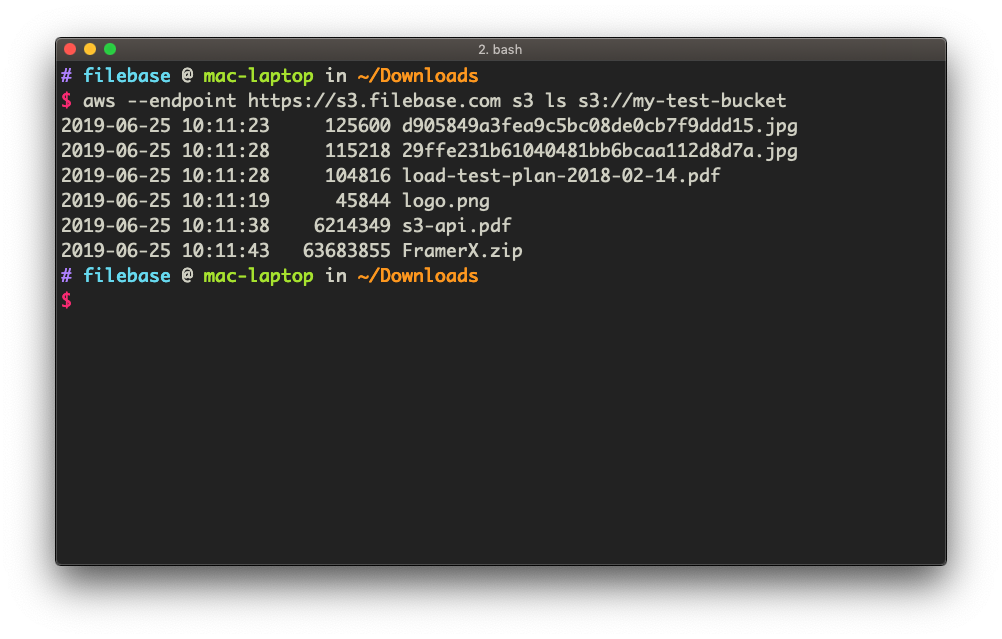
And of course, all files are always available from our browser-based UI console as well:

We can use the s3 cp command to upload a single file:
aws --endpoint https://s3.filebase.com s3 cp s3-api.pdf s3://my-test-bucket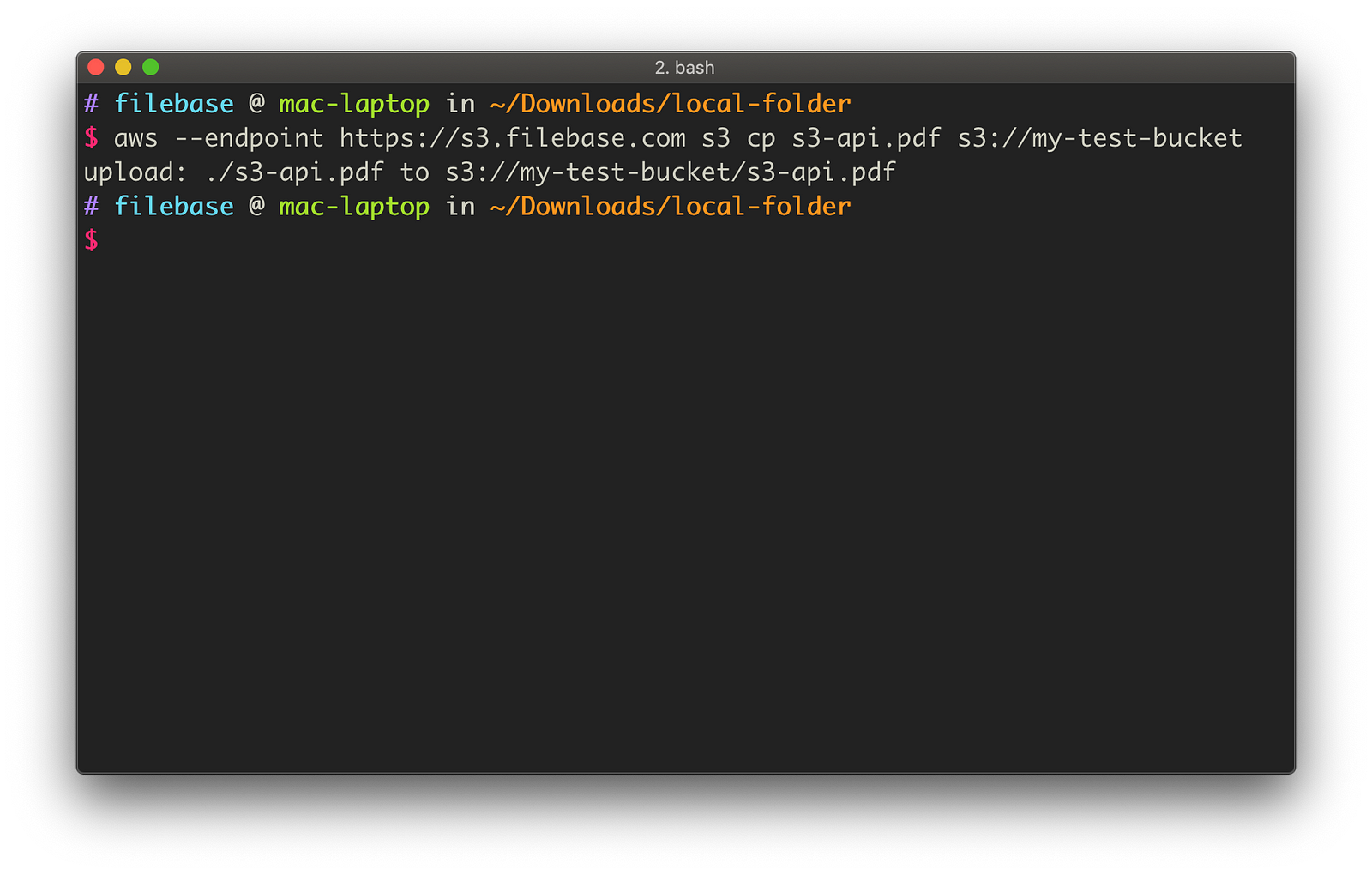
Multipart uploads
The AWS CLI takes advantage of S3-compatible object storage services that support multipart uploads. By default, the multipart_threshold of the AWS CLI is 8MB. This means any file larger than 8MB will be automatically split into separate chunks and uploaded in parallel. Multipart uploading is important because it increases performance and allows for resumable file transfers in the event of network errors.
To upload a file using multipart, simply try uploading a file larger than 8MB in size — the AWS CLI will automatically take care of the rest. In the example below, we will upload a 1GB file.
aws --endpoint https://s3.filebase.com s3 cp 1GB.zip s3://my-test-bucket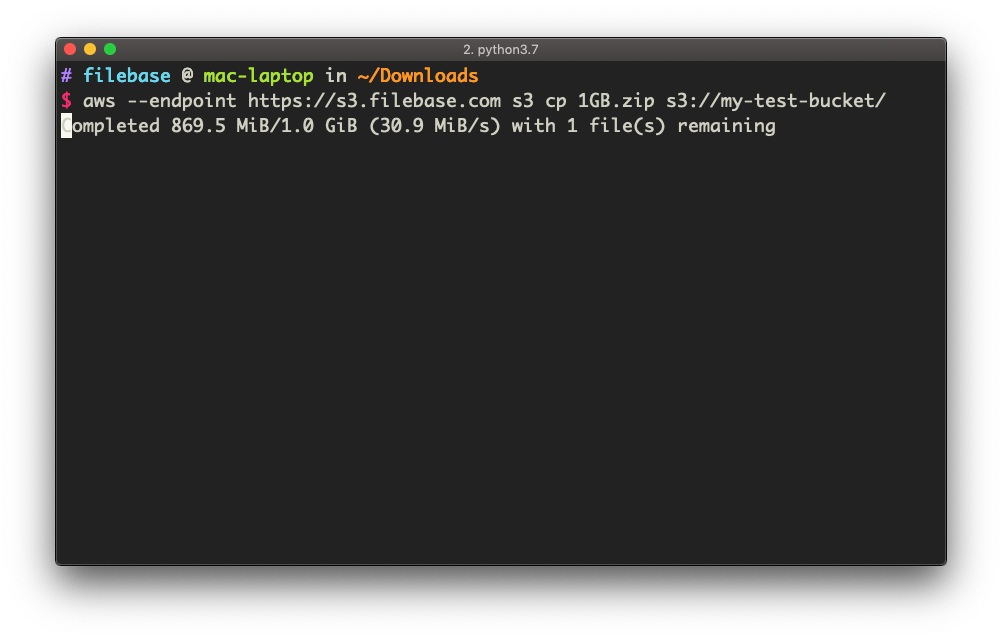
Verifying uploaded files
The AWS CLI can also be used to interact with several other Filebase S3 APIs. For example, we can use the s3api head-object command to fetch object metadata. One of the metadata fields returned by the service is the entity tag, also known as an ETag. With Filebase, the ETag of an object is equivalent to an object’s MD5 checksum. Using the MD5 is a common practice with S3-compatible object storage services.
In the example below, we will fetch the object’s metadata from the Filebase S3 API. After this, we run a command which calculates the MD5 of the same file on our local machine. If the MD5’s match, we can be sure that our upload was successful and the service received our data properly.
aws --endpoint https://s3.filebase.com s3api head-object --bucket my-test-bucket --key 1GB.zipTo calculate the MD5 checksum of our file locally on macOS:
md5sum 1GB.zip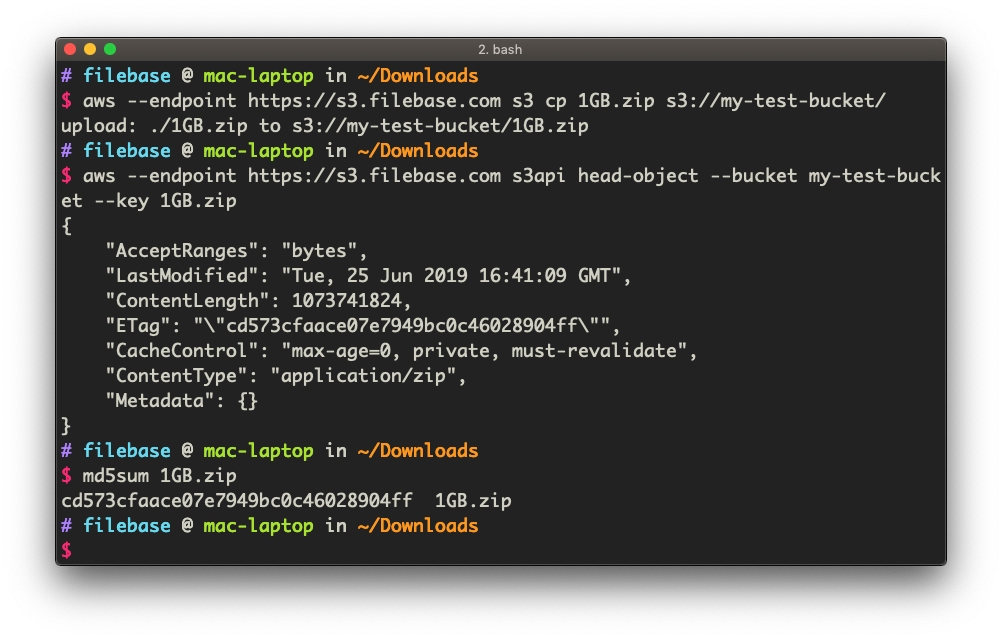
As you can see, the MD5 value of cd573cfaace07e7949bc0c46028904ff matches — therefore we can be assured the service received and processed our file correctly.

Conclusion
Working within the command line isn’t as bad as it seems, but we hope this tutorial was a good start at how to use Filebase within this manner.
Please let us know if you have any questions, comments or concerns at hello@filebase.com
For more information:
Filebase website
Filebase technical documentation
About Filebase
Filebase is the world’s first object storage platform powered by multiple decentralized storage networks. Filebase helps customers save over 90% compared to traditional cloud providers. Additionally, Filebase’s proprietary edge caching technology helps customers achieve industry-leading storage performance when fetching data from decentralized networks.
Filebase was awarded the “Most Exciting Data Storage And Sharing Project” in HackerNoon’s 2020 Noonies Awards and was a finalist in Storage Magazine’s 2019 Product of the Year Awards.
Visit our website and blog, follow us on Twitter and LinkedIn and like us on Facebook.
Reliable IPFS, Zero Headaches
Gateways, IPNS, and seamless pinning—all in one place. Try it now
Get Started For Free!