Introducing support for IPFS, backed by decentralized storage


Over the past two years, the NFT boom has taken the world by storm. Minting NFTs across various blockchains is now commonplace in the crypto world. However the storage of these NFT assets is often overlooked. IPFS, known as the InterPlanetary File System, has become the common standard used to store NFT assets.
One often overlooked detail is that IPFS is not a storage network in and of itself. It is much more of a data routing and transmission protocol. The IPFS network is a collection of nodes exchanging information. File entries can be "pinned" to the public IPFS DHT (distributed hash table) to let other nodes on the network know which hosts are storing which files. The tweet below covers it pretty well.
Here's a secret: @IPFS is NOT a data storage protocol. It's a data routing protocol.
— skøgard (@skogard) February 23, 2022
Start thinking that way and it will take you to a whole new universe.
Within the IPFS ecosystem, there are a number of public gateways. Some of these gateways allow you to upload files, but there is often no guarantee that your file will remain online. Unless a file is explicitly pinned by an IPFS node, the file will simply be removed the next time the garbage collection process runs. This has surfaced a number of issues regarding the storage of NFTs.
To help solve this problem, a few different pinning providers have emerged. For a fee, these providers will allow you to upload your files, and they will keep them actively pinned for you. However this brings a new problem to light: where are these files actually being stored? Somewhere out there, an IPFS server is running and serving content, but where does the content ultimately live?
Filling in the gaps
At Filebase, we've spent a lot of time researching and analyzing this problem. We specialize in building on top of decentralized storage, and our flagship S3 compatible API has processed close to 1 billion files. Just a couple of months ago, we put our thinking hats on and started working on this problem. Here is what we found:
- Most IPFS pinning providers use Amazon S3 and other centralized object storage services under the hood. The "data store" of an IPFS server can be pointed to S3 using a simple plugin.
- Because AWS S3 is being used, providers are charging upwards of ~$150 per TB!
- However, if AWS S3 goes down, your IPFS server goes down too. Unless the data has been cached somewhere, your IPFS CID links are no longer accessible. This can result in an NFT "rug pull".
- A system with this configuration also has the net result of introducing a very fancy way to access AWS S3. If we are so reliant on AWS, why not use a simple HTTP URL instead?
Why not build Web3 with Web3?
We've come up with a solution to address the gaps listed above and we think it will benefit the entire crypto ecosystem. Simply put: Why not build Web3 with Web3?
Today, we are excited to share that Filebase now has support for IPFS!
Now you might ask - what makes this integration unique? It's simple: all files that are pinned onto IPFS using Filebase are actually being stored on Sia, one of the leading decentralized storage networks. This creates an environment where the data storage layer for our IPFS nodes is highly available, and most importantly, geo-redundant. By using a decentralized network for storage, we are no longer reliant on a cloud provider's block storage volume (AWS EBS) or a centralized storage bucket. (AWS S3)
A Filebase edge location could suffer a complete outage, and other locations will simply pick up the slack. This is made possible because the underlying data storage layer is decentralized.
Oh, and there's a massive cost benefit too: This is available to all Filebase users starting today, for $5.99 per TB while in beta. In the future, we may raise this pricing slightly based on usage patterns, but it will be nowhere near $150 per TB.
How do I pin data onto IPFS?
With Filebase, pinning data onto IPFS is easy. You have two options:
- Use our simple drag and drop interface within the Filebase dashboard
- Use our simple S3 compatible API
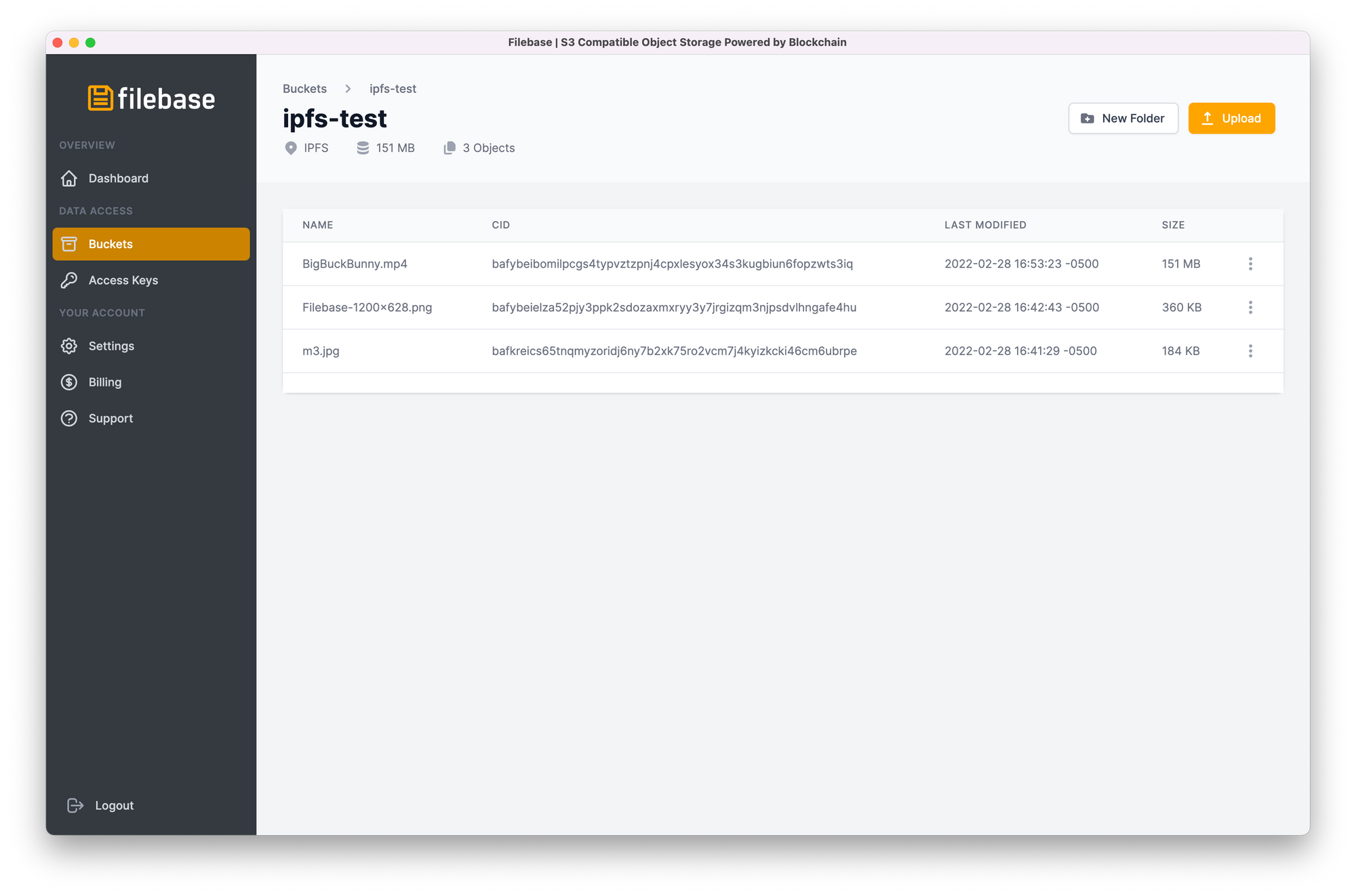
When you upload a file, an IPFS CID (content identifier) will be returned. You can then use this CID to access your data from your own IPFS node, or any other IPFS gateway on the public internet. CID's are clearly displayed within our dashboard, and they can be retrieved programmatically as well.
Once you've opened up an IPFS bucket from the dashboard, a CID column appears. You can click on any CID, and it will be automatically copied to your clipboard.
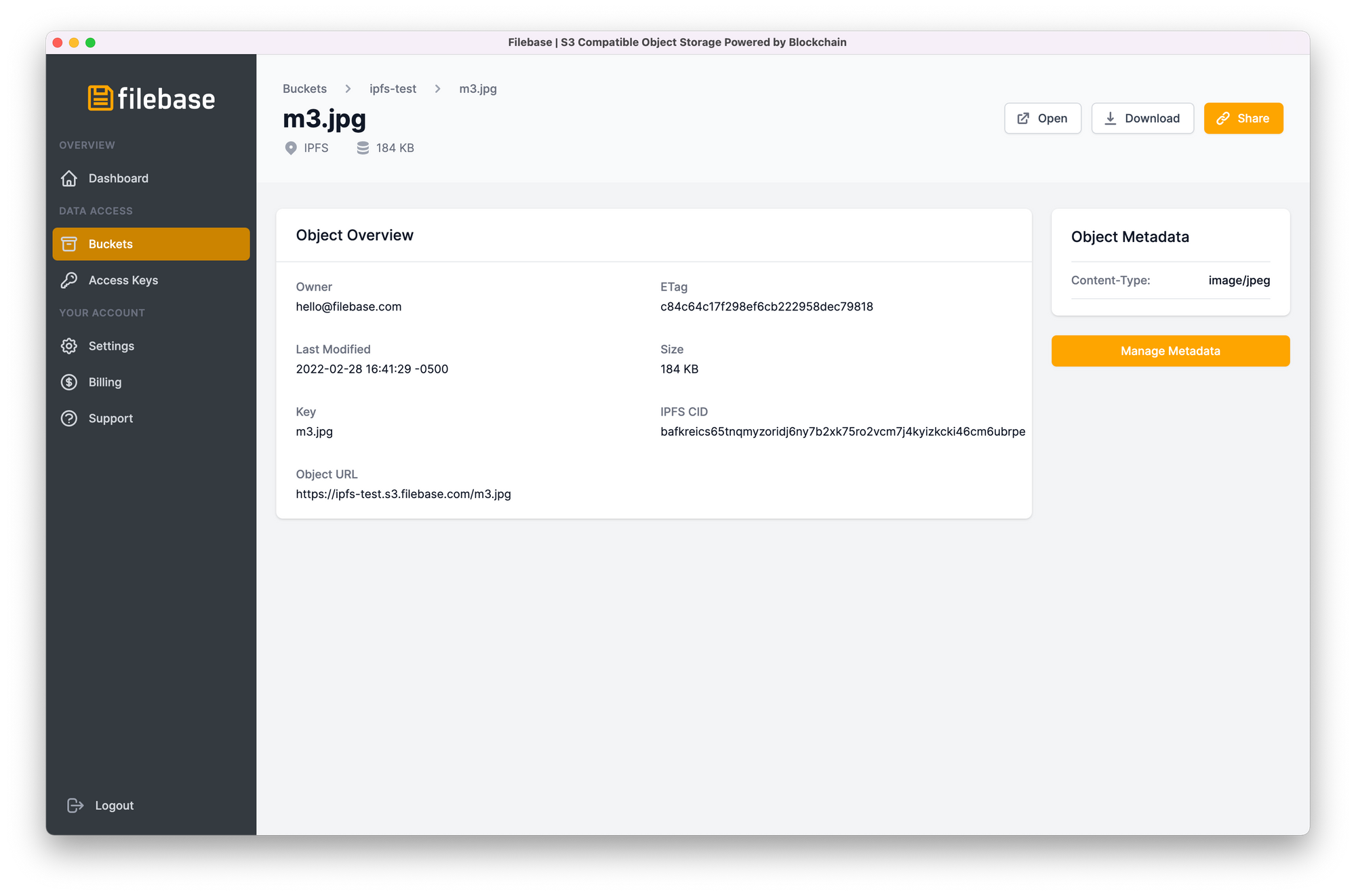
The object overview page will also show you the CID, along with other details:
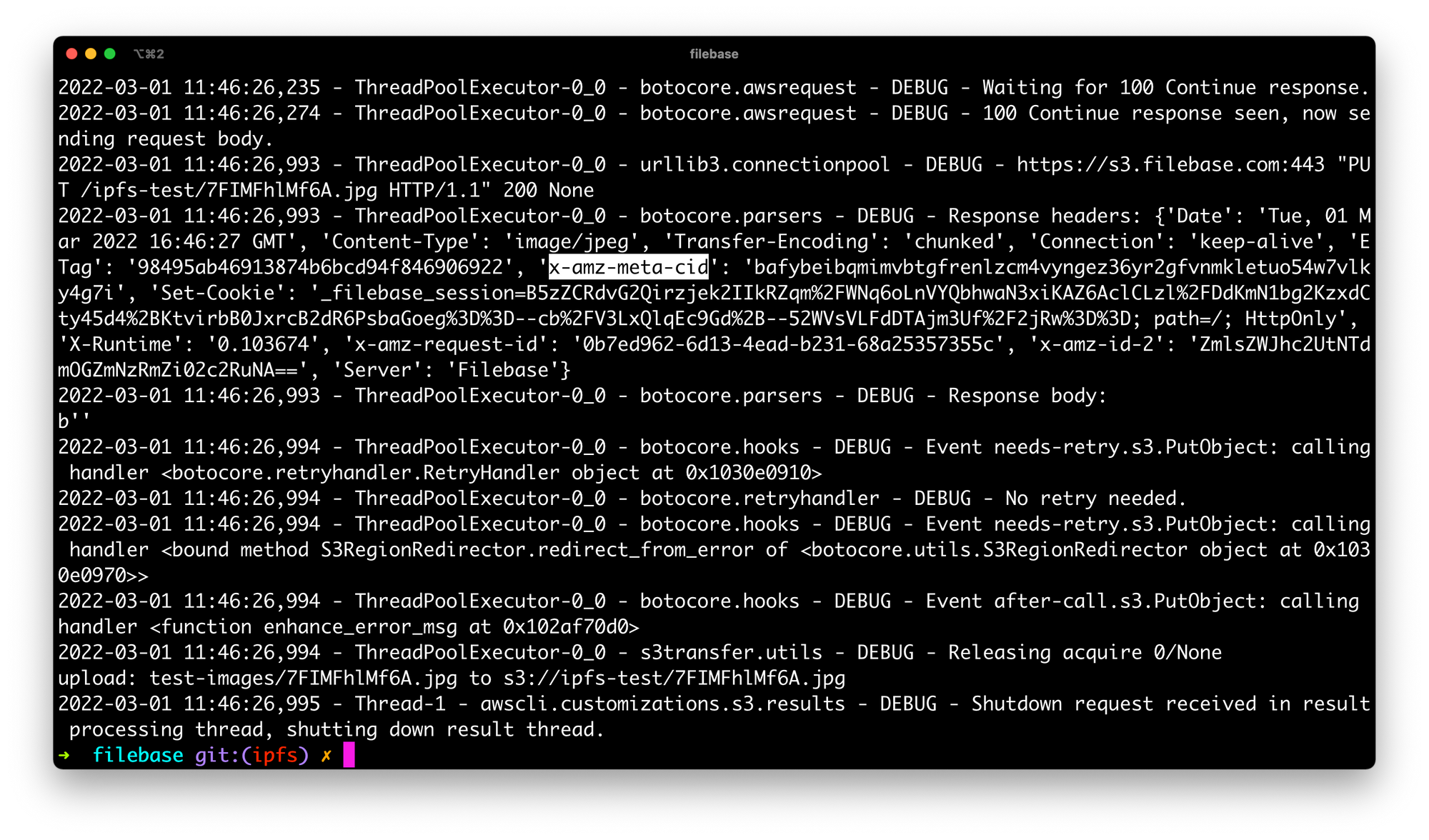
If you're using the S3 compatible API, the CID will be returned in the response of a PutObject call. For example, if we run the following AWS CLI command:
aws --endpoint https://s3.filebase.com s3 cp test-images/7FIMFhlMf6A.jpg s3://ipfs-test --debugThe response is shown below. For convenience, we've highlighted the respective response header:
We can also call the HeadObject API to fetch the CID at any time as well:
aws --endpoint https://s3.filebase.com s3api head-object --bucket ipfs-test --key 7FIMFhlMf6A.jpg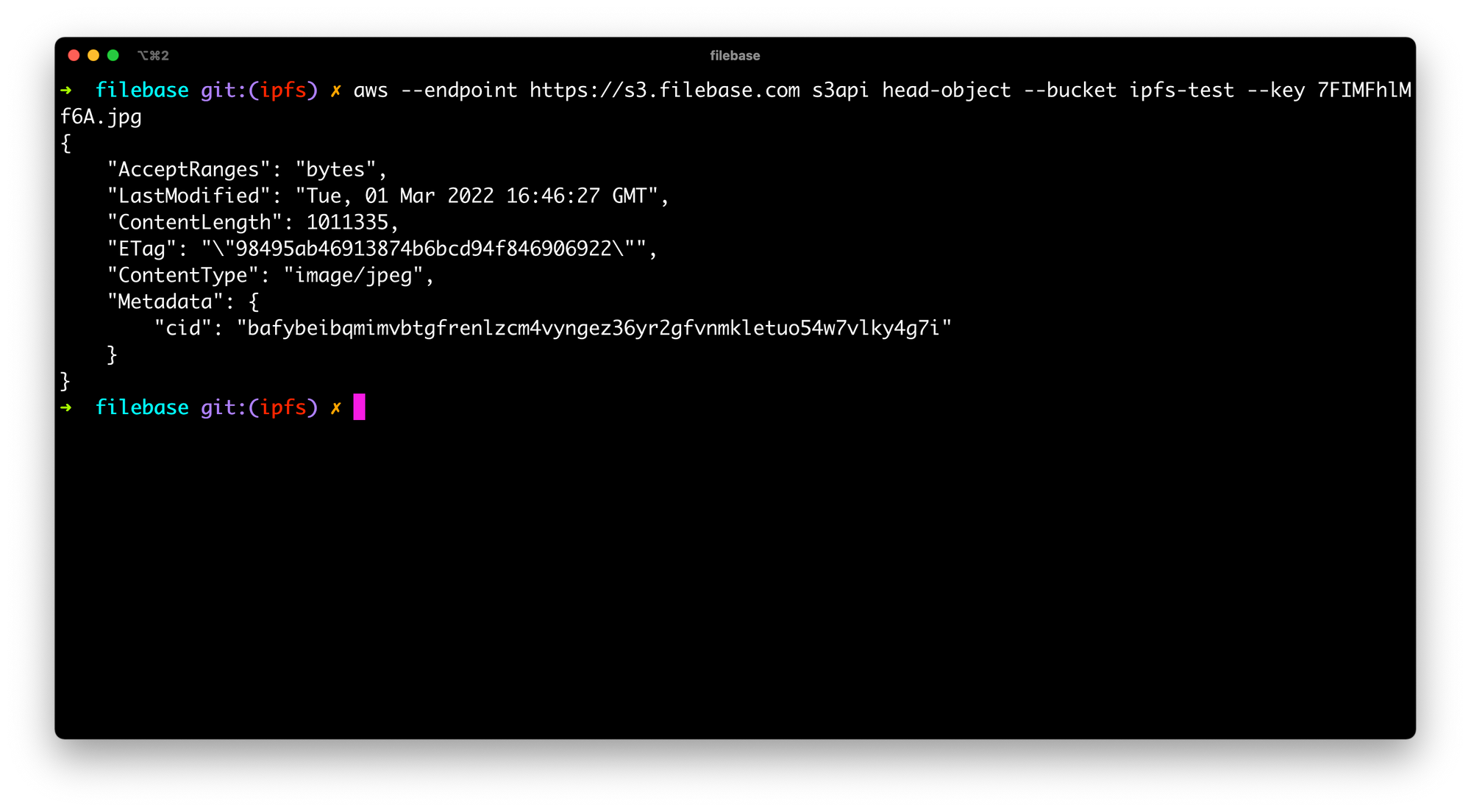
Now that IPFS functionality is live, we plan to continue building out this integration even further! Be on the look out for additional upcoming features!
Enjoy 5TB of free storage for one-month (using code "IPFS")
💾 👉 Deploy to IPFS today!
Questions? Check out our excellent documentation found here, or simply reach out to us: hello@filebase.com or by joining by our Discord.
Update (2023): Filebase no longer supports Sia. While this post originally described our IPFS service as being backed by Sia, that is no longer the case. We announced the sunset of our Sia integration in August 2023, provided a migration window through November 15, 2023, and have since fully retired Sia support from the Filebase platform. For current Filebase product information, please refer to our newer IPFS documentation and product pages.